
データを有効に活用するための考え方
宣伝効果を高めるために、ただ宣伝の量を増やすだけでは経費や手間が膨らみます。
ここでは、宣伝の「量」ではなく「質」を高めることで、いかに中長期的に宣伝のコストや手間を効率化していくかというお話です。
統計学といっても、いろいろな分析方法がありますが、当社ではGISと組み合わせた、独自の商圏分析を行い業種や客層に応じた宣伝戦略策定のお手伝いや提案をいたします。
基本的にはアンケートやPOSデータ、顧客情報データ、Webのアクセス解析、アンケートなどのデータから、おおまかな顧客層の傾向や宣伝戦略の方向性を探るための目安を得ることを目的とし、専門のマーケティング会社のような本格的な統計分析を行うものではございません。
GISが「地理情報の視覚化」であるのに対し、統計分析は「数値情報と可能性の可視化」といえます。GIS(地図情報システム)では、お客さんの「地理的な分布や情報が把握」できますが、さらに統計分析を連携させることでお客さんの来店動機や傾向などの側面を立体的に検証することができます。
いづれも現実を視覚的情報としてわかりやすく表現できるため、社内における情報の共有化及び会議などで適切な判断を引き出すための強力なツールになります。

統計学及び統計分析の内容や計算過程についてはかなり複雑なので、ここで全てをわかりやすく説明することはできませんが、私なりに端折った表現をしますと、お店や企業で記録している、お客さまデータからマーケティングや宣伝に必要な情報を視覚化したり、仮説の検証に役立てようということです。
お客さんについてのデータ(顧客データ)は、大なり小なり独自に収集、記録している企業(店舗)様は少なくありませんが、問題はそれをどの程度有効活用できているかということです。統計学における分析手法も目的に応じていろいろなものがありますが、ここではカンタンでわかりやすい事例と考え方を紹介します。
例えば、数字が羅列されているだけの顧客データを単純にグラフや表にまとめて視覚化するだけでも判断材料としての精度は高まりますが、ここではさらにそれを数歩進め統計学的な分析によって、どのようなことがわかり、またそれがどのように解決策への近道になる得るかということをカンタンにまとめます。
データ分析の目的と仮説
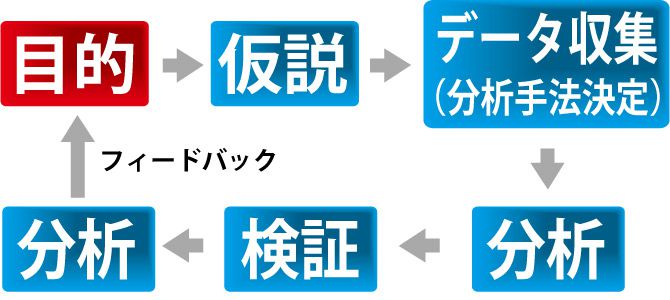
まず一口に売上と言っても、「なぜ売れるのか?」あるいは「なぜ売れないのか?」というのは必ず理由があります。
しかし多くの場合、その「理由」を決めるにあたって主観的イメージで、漠然としたものである場合が多いのです。
現状把握がもし的外れであった場合、当然その対策も現実からズレてしまい最終的な目的を達成することはできません。
そこで、まず正しい現状把握を行い「仮説」を立て、これが果たしてどれくらいの精度があるかを分析したり、確認するためにデータを使います。
例で言えば「リピーターを増やしたい」というのが目的である場合、それに対する仮説の一つが「距離との因果関係」等です。なぜいちいち仮説を立てる必要性があるのかといいますと主に次の理由があります。
1)分析の目的を明らかにし、対策のブレをなくす。
先ほどの「距離とリピーター」の関係一つとっても、そのイメージは個々にイメージ(主観)が異なります。
例えばAさんは「そんなの関係ない」といい、Bさんは「いや絶対に関係性はある」と意見が割れた場合、どちらが正しいかを判定するのは困難であり、つまり仮説とは「個人のイメージ、思いつき」に過ぎません。
しかし、これをデータ解析をすることで「AさんとBさんの意見のどちらに、どのくらいの信憑性があるか?」を数字で現すことができますので、間違った仮説に基づいた対策をたてたりせず時間と労力のムダがなくなり、データの視覚化により意見=対策のブレがなくなります。
2)多角的な視点から信頼性のある対策を行うことができる。
次に「売上が落ちている原因と対策」を考える場合、「価格が高い?」「店員の対応?」「商品の魅力がない?」「宣伝が足らない?」・・などなど、おもいつく要因は必ずいくつか出てきます。
このような複数の仮説に対し、それをデータ分析で検証することで仮説の優先順位と信憑性などがわかります。
仮説の検証と対策の立て方は極めて重要であり、ここが間違っていると、その後の作業がムダになるほか、いつまでも結果が伴いません。
データ収集と分析手法について
目的にあった仮説を立てたら、それを検証するためデータが必要です。
データの収集法はさまざま方法がありますが、昔ながらのアンケートや会員名簿、POSデータ、Webのアクセス解析など目的と仮説にあわせ必要なデータを収集します。また、一口に統計学分析と言っても目的によってそれぞれ分析方法は異なります。
●相関
相関は2つのデータ間の規則性を持って直線的に同時に変化するものをいい「正」と「負」の2通りの相関があります。両者間に関連性が認められることを「相関関係がある」といい、
例えば学年が上がると身長が高くなる。(正の相関)
リピート客の数→距離が大きくなると減少(負の相関)といいこの関係の程度を表す値を相関係数といい「+1.0~-1.0」の範囲で現します。
●回帰分析
多変量解析の1種で、要因xとy間の因果関係を回帰式を使って分析する手法です。予測と要因分析などに有効です。
●主成分分析
多変量解析の1種で、データ項目間の関連を分析し、多くの要因を絞り込む手法です。
●その他
ヒット商品のコンセプト開発、マーケティングでよく使われるコンジョイント分析や、クラスター分析等(多変量解析)、「個性」「経験」や「勘」や「常識」を取り込むことで、確率論では取り扱うことの難しい分析が可能なベイズ統計などがありますが当社で扱うものは主に確率論の多変量解析です。
分析
では、例として「お店から距離が近い人ほど来る確率が高くリピート客になっている可能性が高いのではないか?」という仮説、言い換えれば「距離と売上には因果関係はあるの?」という仮説の検証です。
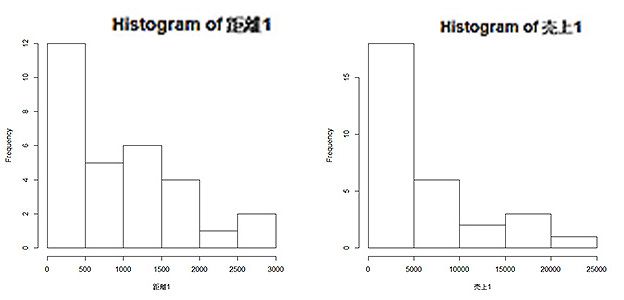 そこでお客さんの30人分の住所情報と売上データをもとに両者の相関を調べてみましょう。
そこでお客さんの30人分の住所情報と売上データをもとに両者の相関を調べてみましょう。
これをヒストグラムにすると、それぞれのお客さんの距離と使った金額の分布が示されます。数字の羅列ではイメージとして捉えられなかったものがこのようにグラフ化するとわかりやすくなりますね。これもデータの視覚化の一つです。
●相関係数
前述したように相関係数は、2つのデータがどの程度の関連性があるかということを分析するもので「+1.0~-1.0」の間の数字で表し、数値の判断基準は下記のようになります。
「強い正の相関」・・・1.0~0.7
「正の相関あり」・・・0.7~0.5
「相関なし」・・・・・0.5~-0.5
「負の相関あり」・・・-0.5~-0.7
「強い負の相関」・・・-0.7~-1.0
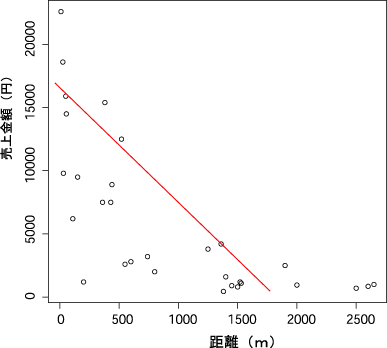 さて、冒頭のヒストグラムのデータを使い「売上」と「距離」の相関係数を計算すると約「-0.706」となります。
さて、冒頭のヒストグラムのデータを使い「売上」と「距離」の相関係数を計算すると約「-0.706」となります。
これをプロット図にしてみましょう。
グラフ内の○は、お客さんの個別の売上とお店からの距離を現しており、傾向を示す赤い線は右方下がり(負の相関)になっています。
●信頼度の検定
この場合、相関係数が-0.706なので「距離と売上の因果関係がある」という仮説は「イメージ」ではなく、数字による信頼度は「強い相関がある」ということがわかります。(95%信頼区間の上限値は -0.8499567、下限値は -0.4633795)
実際にはデータ数が「30」では少なすぎて信憑性に欠けますが、ここでは分析の考え方の紹介というのが目的ですのでグラフが見易くなる程度に抑えています。
対 策(距離から売り上げを予測する)
 さて、次に距離とお客さんの売上には関連があるいう仮説が正しいとして、折込チラシの配布を考えてみましょう。
さて、次に距離とお客さんの売上には関連があるいう仮説が正しいとして、折込チラシの配布を考えてみましょう。
このお店では、前回チラシを3kmの範囲でまいたのですが、今回はどうすべきか単回帰分析を使い簡単な予測値を分析してみます。
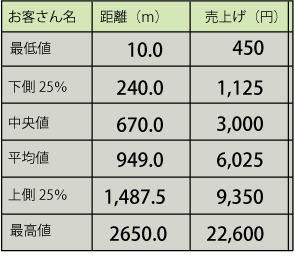
先ほどのデータをみると一番近い人は10mの距離から、遠い人は2650mで全体の平均は約950mでした。
同じく客単価は、最小の人で450円、最も多く利用した人が22,600円で、平均的な客単価は約6,025円/月です。
ここから、お客さんの住所と、お店の距離、客単価の売上から単回帰式を求め、それを計算してみたところ右のような予測値になります。
<単回帰分析における売上予測>
3000kmの場合・・・-4,882円
2500kmの場合・・・-2,222円
2000kmの場合・・・・+ 437円
1000kmの場合・・・ +5,757円
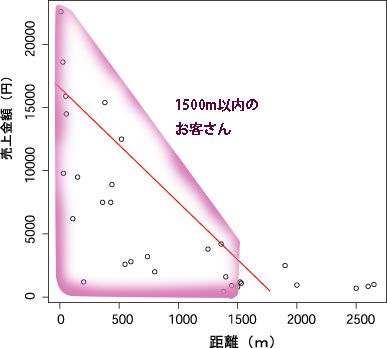 この結果からすると2000mまではプラスですが、2500m以上離れるとマイナス、つまり「売上はあまり期待できない」ということになります。先ほどのヒストグラムでみると確かに1500m以上のお客さんは少ないイメージがありますね。(右図参照)
この結果からすると2000mまではプラスですが、2500m以上離れるとマイナス、つまり「売上はあまり期待できない」ということになります。先ほどのヒストグラムでみると確かに1500m以上のお客さんは少ないイメージがありますね。(右図参照)
今回、チラシを30,000枚配布する計画であれば、2通りの考え方ができます。
(1)2km圏内の内側エリアに何度か集中してまいたほうが費用対効果は高そう。
(2)逆の発想で魅力的なキャンペーンを企画した上で3km圏内にまで配布して新規客を拡大しよう。
・・・さて、このうち「どちらの案を採るべきか?」が、本来の会議の議案で同じテーマで会議を行うにしても、情報をこのように整理・理解して参加した場合と、そうでない場合では参加者の意見や対策も異なるのではないでしょうか。
会議は参加者の主観を極力排し、現状の状況を正確に把握・共有した上で対策を論じることでアイディアや議論がぶれなくなります。このような手順で実施した対策を実践に移し、更に改善するためのテーマと必要なデータを収集し、さらなる検証を行っていきます。
因子分析
因子分析とは、データの中から潜在的な要因(説明変数)を見つけ出す分析方法です。
ここでは、お客さんが自分のお店に来る理由、他店と比較した場合の強みなどを推定しお客さんの絞込みや宣伝活動に活かそうというものです。
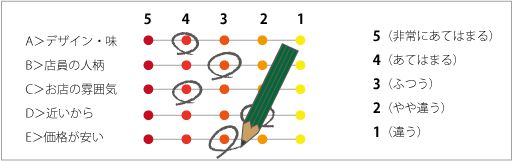 例として、とあるケーキ屋さんに来たお客さんから満足度アンケートをとってみたとします。
例として、とあるケーキ屋さんに来たお客さんから満足度アンケートをとってみたとします。
アンケート用紙には「このお店をご利用いただいた理由」という欄を設けそれぞれ回答は5段階評価です。
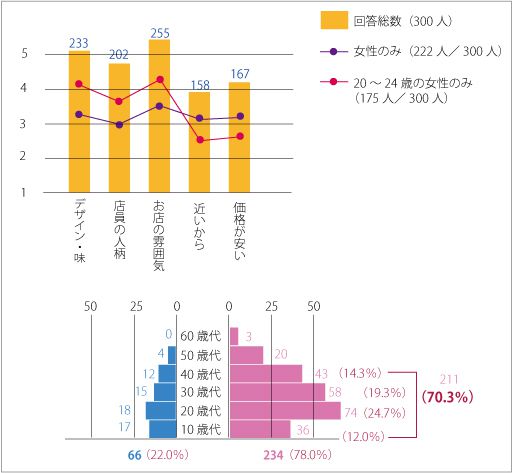
アンケートの有効回答総数は300で複数回答可とした結果、この様な結果がでました。
 <図-1>
<図-1>
こうして<図-1>をみると、このお店のメイン客層は20~40歳代の女性客のようですね。10代の女性も含めると全体の70%を閉めています。さらにこれを年齢別にグラフ化(図ー2)してみましょう。
 <図-2>
<図-2>
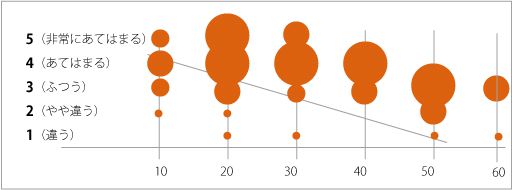
<図-2>では、男女を含めて評価別に回答数を示したもので、●が大きいほど数が多くなっており
世代別の評価が一目瞭然ですね。次に、このデータを基に「因子分析」をしてみます。
「お店の雰囲気」「店員の人柄」「ケーキのデザインと味」「お店との距離」「価格」といったアンケートで評価してもらった項目を並べ、それを統計学的に分析します。
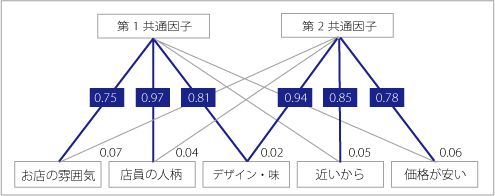 計算方法は省略しますが、青枠の中に「0.75」「0.97」「0.81」という数字が入っています。これを「因子負荷量の絶対値」といい大きいほど目的変数に影響を及ぼしていると解釈し、目安として「0.5」以上のものは影響が大きいと判断します。
計算方法は省略しますが、青枠の中に「0.75」「0.97」「0.81」という数字が入っています。これを「因子負荷量の絶対値」といい大きいほど目的変数に影響を及ぼしていると解釈し、目安として「0.5」以上のものは影響が大きいと判断します。
「お店の雰囲気」という項目では、「第1共通因子(目的変数)」との関連性は「0.75」と高い数値を示していますが、「第2共通因子」との関連性は「0.07」と非常に低い値です。
一方、「ケーキのデザインと味」は第1、2両方の共通因子に大きな影響を与えていますね。
因子分析は、この第1と第2の「共通因子」には何が当てはまるかを推定するのですが、第1の共通因子は「お店のイメージ」、第2の共通因子は「実用性」といった感じでしょうか。
仮に1年後、このお店での売上が上がったり、逆に減少したとき、このようなデータを継続してとることで「1年前と比較して何がよい(あるいは悪いのか?)」ということを客観的に判断することができ、経営・人事・宣伝における判断材料(指標)となります。
ところで、「このような分析が果たして信用できるのか?」を確認するのに「累積寄与率」という数値があり、50%以上なら分析は根拠のあるものとみなします。上記の例では約78%という数字が出たため参考に足ると解釈することができます。
当社ではGISやその他のマーケティング理論も併用した、より精度の高いコンサルティングを行っております。御社の眠ったままの貴重なお客さまデータをGISを使って有効活用してみませんか?
